
상태 저장 효율화를 통한 디스크 공간 절약하기
Kaia 아카이브 노드를 대상으로 한 FlatTrie의 실험적 도입


아카이브 노드의 딜레마
Kaia의 풀 노드(full node) 저장 공간은 규모면에서 관리 가능한 수준이라고 볼 수 있습니다. 하지만 아카이브 노드는 이보다 5~10배 많은 공간이 필요합니다. 가령 메인넷 풀노드가 5TB 공간을 차지한다면, 아카이브 노드는 35TB 이상의 저장 공간을 잡아먹습니다. 이중 대부분(31TB)은 블록체인 상태 데이터베이스로, 여기에는 각 계정의 잔액, 스마트컨트랙트 변수, 모든 블록 높이에 따른 상태 변화가 저장되어 있습니다.
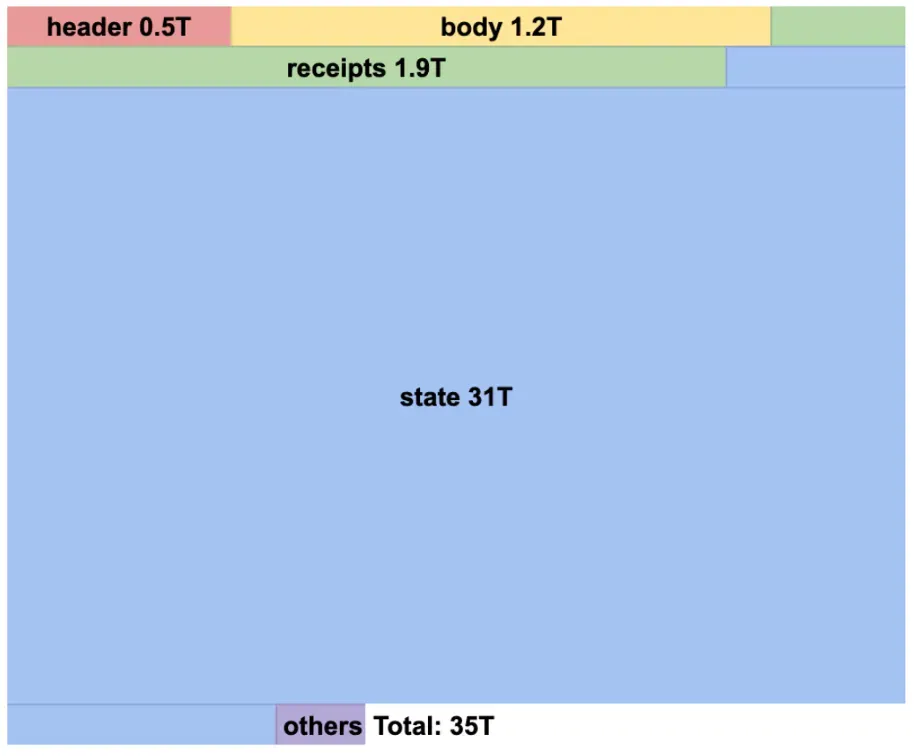
아카이브 노드는 전체 이력을 유지합니다. 풀 노드는 오래된 상태를 프루닝(정리)할 수 있지만, 아카이브 노드는 데이터 분석, 블록 탐색기, 포렌식 툴 등을 위해 과거 데이터가 반드시 필요합니다. 이로써 “2023년 1월 1일 이 지갑의 USDC 잔액은 얼마였나?”와 같은 쿼리에 답할 수 있게 됩니다.
Kaia의 이전에 상태 마이그레이션 (2021년)과 라이브 프루닝 (2023년) 기능을 도입해 풀 노드의 공간 부담을 완화했습니다. 하지만 아카이브 노드에는 삭제가 아닌 다른 접근 방법이 필요했습니다.
Kaia v2.1.0에서는 FlatTrie라는 아카이브 노드 전용 상태 저장 구조가 실험적으로 도입되었습니다. 기존 아카이브 노드의 스토리지 요구량을 35TB에서 10~20TB까지 줄일 수 있을 것으로 기대되며, 실제 Kairos 테스트넷에서 75% 이상의 저장 공간 절약 효과가 확인되었습니다.
Merkle Trie의 데이터 중복 문제
EVM 블록체인(예: 이더리움, Kaia)은 Merkle Patricia Trie(머클 패트리샤 트라이, 이하 MPT)를 사용해 상태를 처리합니다. 각 블록은 월드 스테이트(world state, 네트워크 전체 계정 상태 집합) 전체를 증명하는 32바이트 해시(state root)를 생성하며, 이를 위해 계정 잔고, 컨트랙트 저장소 등의 리프 노드(leaf node)와 이를 엮는 브랜치 노드(branch node)를 트리 형태로 저장합니다.
문제는 아카이브 노드가 수억 개 블록의 트리를 모두 개별적으로 저장하면서, 변경이 없는 노드도 중복 저장된다는 점입니다. 즉, 매 블록마다 거의 동일한 브랜치와 리프 노드가 반복 저장됨에 따라 테라바이트 단위의 중복 데이터가 쌓입니다.
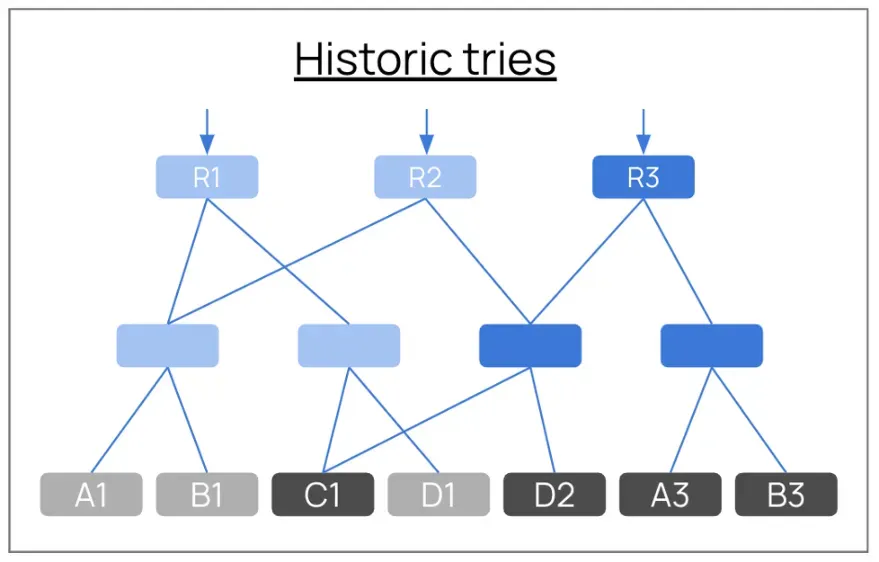
다이어그램을 통해 문제를 살펴보겠습니다. 블록 루트 R1은 전체 트라이를 저장합니다. 트리 구조를 구성하는 브랜치 노드와, 실제 계정 데이터가 있는 최하위 리프 노드 A1, B1, C1, D1이 있습니다. 블록 R2는 또 다른 전체 트라이를 저장합니다. 리프 노드 A1, B1, C1은 동일하지만 D1 대신 D2가 새로 추가되었습니다. 반면 브랜치 노드는 전체가 중복됩니다. 블록 R3에서도 리프 노드에는 변경되지 않은 C1과 D2, 변경된 A3과 B3가 있지만 브랜치 노드는 역시 중복됩니다. 이렇게 2억 개의 블록이 쌓이면 중복된 브랜치 노드들이 어마어마하게 누적됩니다.
Erigon의 해결책: 리프 노드만 저장하기
Ethereum 클라이언트 Erigon은 과거의 브랜치 노드를 저장하지 않아도 된다는 점을 실증했습니다. 아래 다이어그램을 통해 살펴보겠습니다.
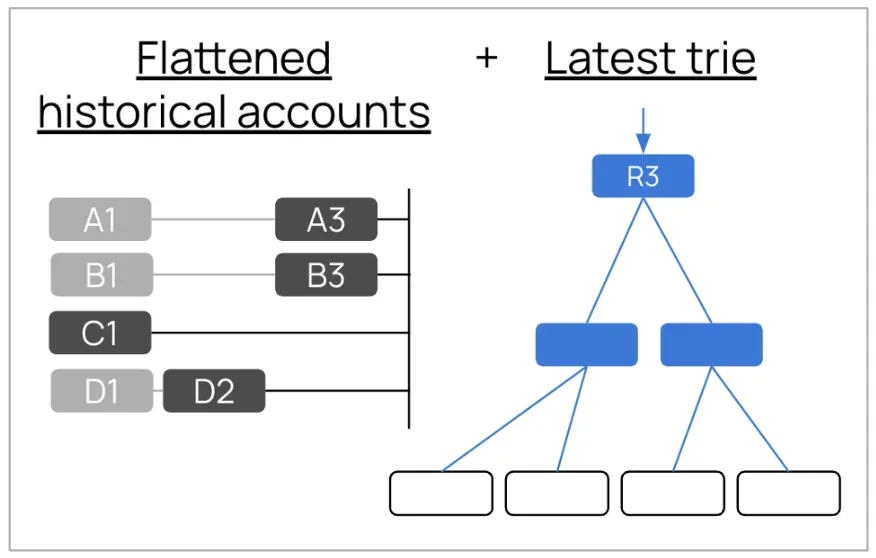
- 각 계정의 과거 데이터(계정 A의 A1과 A3, 계정 B의 B1과 B3, 계정 C의 C1, 계정 D의 D1과 D2)는 중복이 제거되고 평탄화된(Flattened) 형태로 리프 노드에 저장됩니다.
- 최신 블록(현재 상태)인 R3만 빠른 쓰기 및 머클 루트(Merkle root) 계산을 위해 완전한 트라이 구조(브랜치 노드 + 리프 노드)를 유지합니다.
- 과거 블록 R1과 R2에 대한 완전 트라이 구조는 폐기됩니다.
만약 과거 머클 증명을 필요하다면 플랫 데이터에서 트라이 조각을 다시 구성해 이를 되살릴 수 있습니다. 다만 이 과정에서 많은 연산 자원이 소모됩니다.
Erigon은 이더리움 아카이브를 13TB에서 3TB로 줄였습니다(2023년 데이터 기준). Go-ethereum은 최근 경로 기반 상태 스킴(path-based state scheme)에서 이 아이디어를 채택했으며 (2025년 6월), 그 결과 아카이브 용량을 20TB에서 2TB 수준으로 줄였다고 보고했습니다. Polygon 역시 아카이브 노드에 Erigon을 권장합니다.
Kaia의 계정 포맷 문제
Erigon 방식을 Kaia에 적용하는 과정에서 크게 두 가지 기술적 문제가 발생했습니다. 첫째, 계정 구조의 차이입니다. Erigon의 코드는 이더리움의 계정 구조를 기반으로 작성됩니다.
Ethereum: RLP([nonce, balance, storageRoot, codeHash])
Kaia: type || RLP([[nonce, balance, humanReadable, accountKey],
storageRoot, codeHash, codeInfo])하지만 Kaia는 역할 기반의 다중 키 계정이나 주소 변경 없이 키 쌍을 변경할 수 있는 등의 독자적인 기능을 지원합니다. 이 때문에 RLP 인코딩 형태가 다릅니다. Merkle 루트를 계산하는 Erigon의 HexPatriciaHashed(HPH) 모듈은 이더리움 계정 구조는 파싱할 수 있지만, 이와 다른 Kaia의 계정 구조를 처리할 수 없습니다.
해결책: HPH를 수정해 계정을 내부 구조를 들여다보지 않는 불투명한(opaque) 바이트 문자열로 다루도록 했습니다. 구조를 파싱하지 않고 바이트 그대로 해시를 계산하는거죠. 이렇게 함으로써 특정 인코딩이나 계정 포맷에 묶이지 않는 포맷 독립적인(format‑agnostic) 구현이 가능했습니다.
다중 스레딩 제약 문제
두번째는 스레딩 제약 문제입니다. Erigon의 데이터베이스(MDBX)는 단일 스레드 트랜잭션만 지원합니다. 반면, go-ethereum에서 파생된 Kaia의 코드는 여러 goroutine이 동시에 DB에 접근해야 하며, 각각의 스레드에서 별도의 Trie 인스턴스를 쓸 수 있어야 합니다. MDBX는 이러한 패턴을 허용하지 않으며 반드시 단일 스레드에서만 트랜잭션을 사용해야 합니다.
해결책 #1: DomainsManager
각각 고유한 MDBX 데이터베이스 트랜잭션을 소유하는 워커 스레드(worker thread)를 개발했습니다. Kaia 코드는 Go 채널을 통해 작업을 전송합니다. 각 워커는 자체 트랜잭션 컨텍스트 내에서 작업을 실행하고 결과를 반환하여 MDBX의 단일 스레드 요구 사항이 위반되지 않도록 보장합니다.
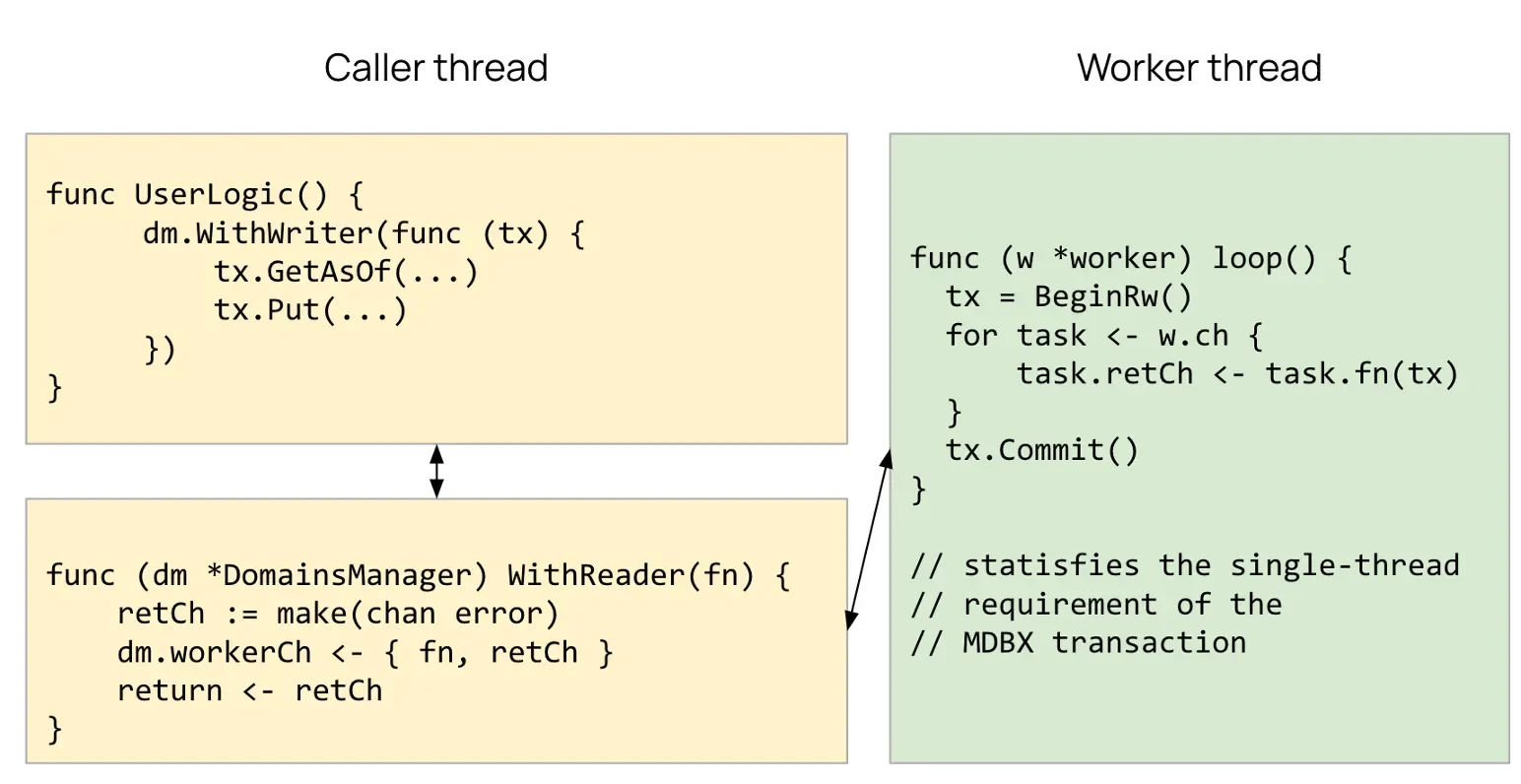
이로써 Kaia의 멀티스레드 인터페이스를 유지하면서 MDBX의 단일 스레드 요구사항을 충족합니다.
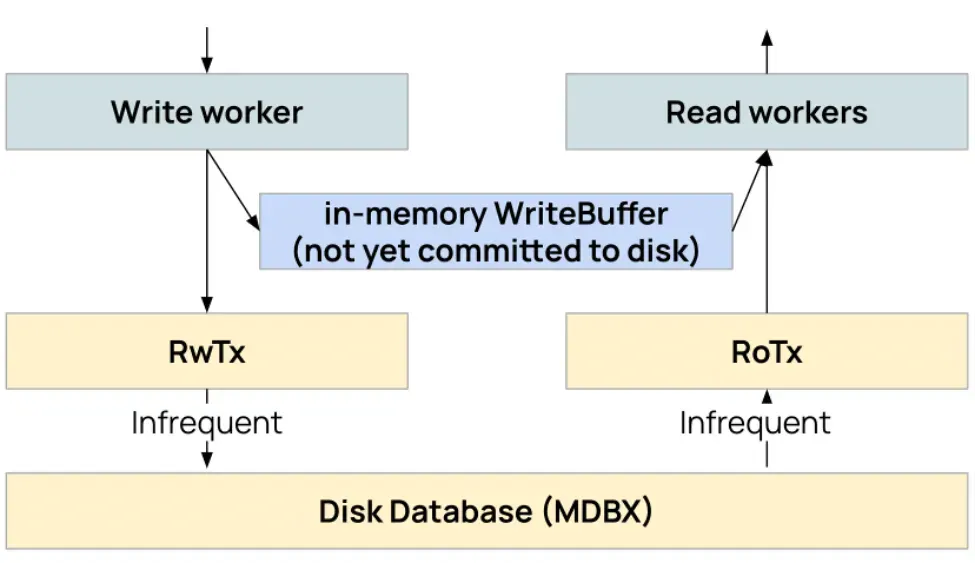
해결책 #2: WriteBuffer
이 과정에서 새로운 문제가 발생했습니다. 한 트랜잭션에서 커밋되지 않은 쓰기 작업이 다른 워커의 읽기 전용 트랜잭션에서는 보이지 않는 문제입니다. 매번 쓰기 이후에 바로 커밋하면 디스크 I/O 오버헤드가 감당할 수 없을 정도로 커지게 됩니다.
해결책으로 워커들이 함께 사용하는 인메모리 레이어인 WriteBuffer를 추가했습니다. 쓰기 작업은 먼저 이 버퍼에 기록되고, 읽기 작업은 디스크에 접근하기 전에 버퍼를 먼저 확인 후 이루어집니다. 커밋은 각 연산마다가 아니라, 일정한 간격으로 모아서 수행합니다.
해결책 #3: DeferredContext
블록 하나를 처리하려면 하나의 AccountTrie와 N개의 StorageTrie(컨트랙트마다 하나씩)가 필요하며, 이들이 만들어내는 모든 변경 사항은 최종적으로 하나의 HPH로 모여 블록의 상태 루트를 계산합니다.
DeferredContext는 이 흐름을 조정하는 컴포넌트로, Kaia의 Trie 인터페이스와 Erigon의 머클 해셔(HexPatriciaHashed)를 이어주는 브리지 역할을 합니다. 모든 트라이에서 발생한 업데이트를 모아 여러 단계의 버퍼를 거쳐 적절한 타이밍에 HPH로 흘려보냅니다.
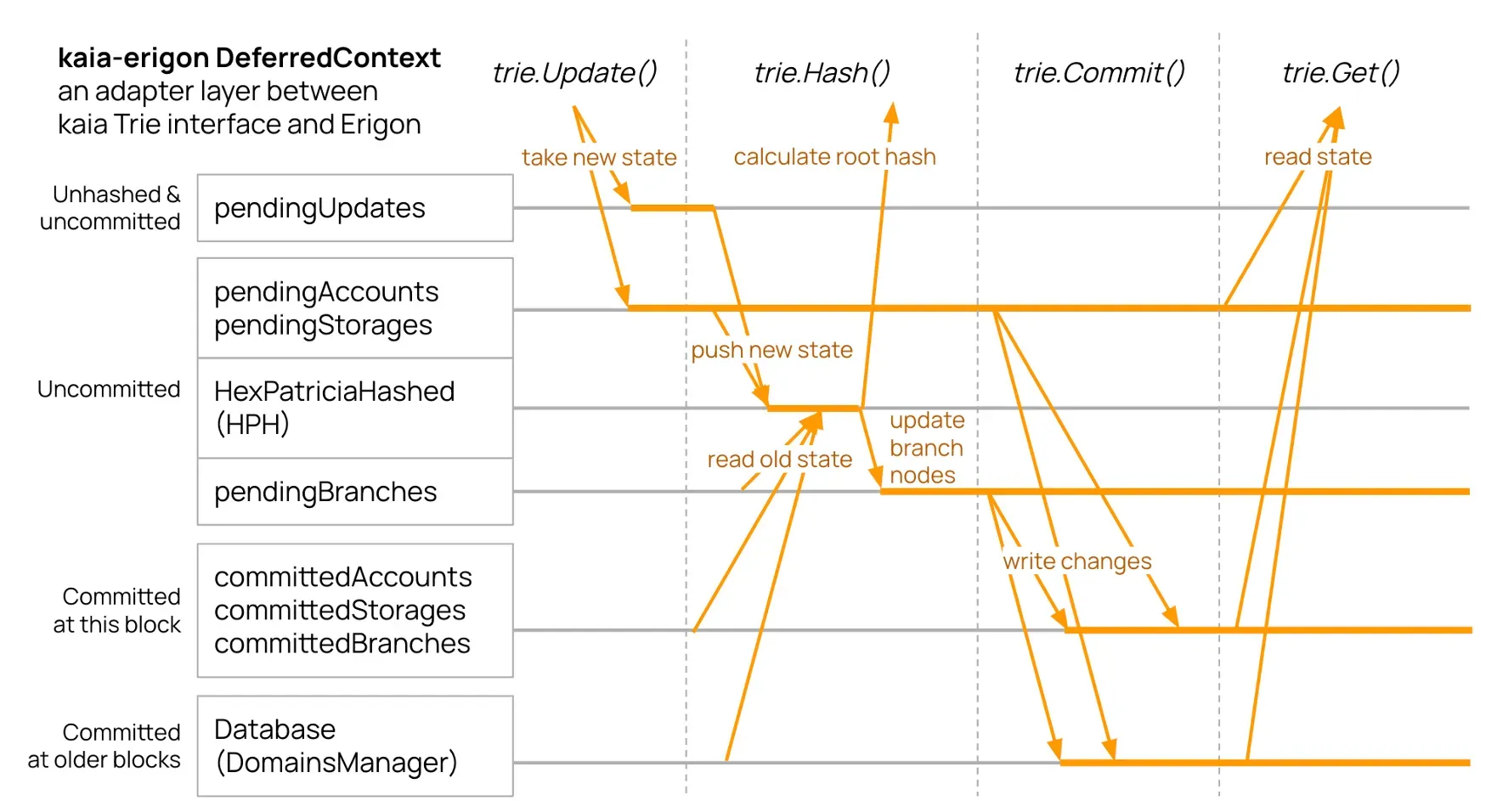
여러 개의 버퍼가 커밋 상태에 따라 서로 다른 데이터를 관리합니다. 아직 해시되지 않은 변경분, 해시되었지만 커밋 전인 변경분, 현재 블록에 커밋된 데이터, 과거 블록에 이미 커밋된 데이터가 각각 별도로 유지됩니다. 각 Trie 연산(Update(), Hash(), Commit(), Get())은 이 레이어들을 올바르게 통과하도록 설계되어 있습니다.
수정된 전체 코드는 여기에서 확인할 수 있습니다.
Kairos 테스트 결과
Kairos 테스트넷에서 아래 세 가지 설정으로 여러 주간 동기화 테스트를 수행했습니다:
- en1: FlatTrie 아카이브 ( — state.experimental-flat-trie)
- en2: 기존 아카이브 ( — gcmode archive — state.block-interval 1)
- en3: 기존 풀 노드 (기본값)
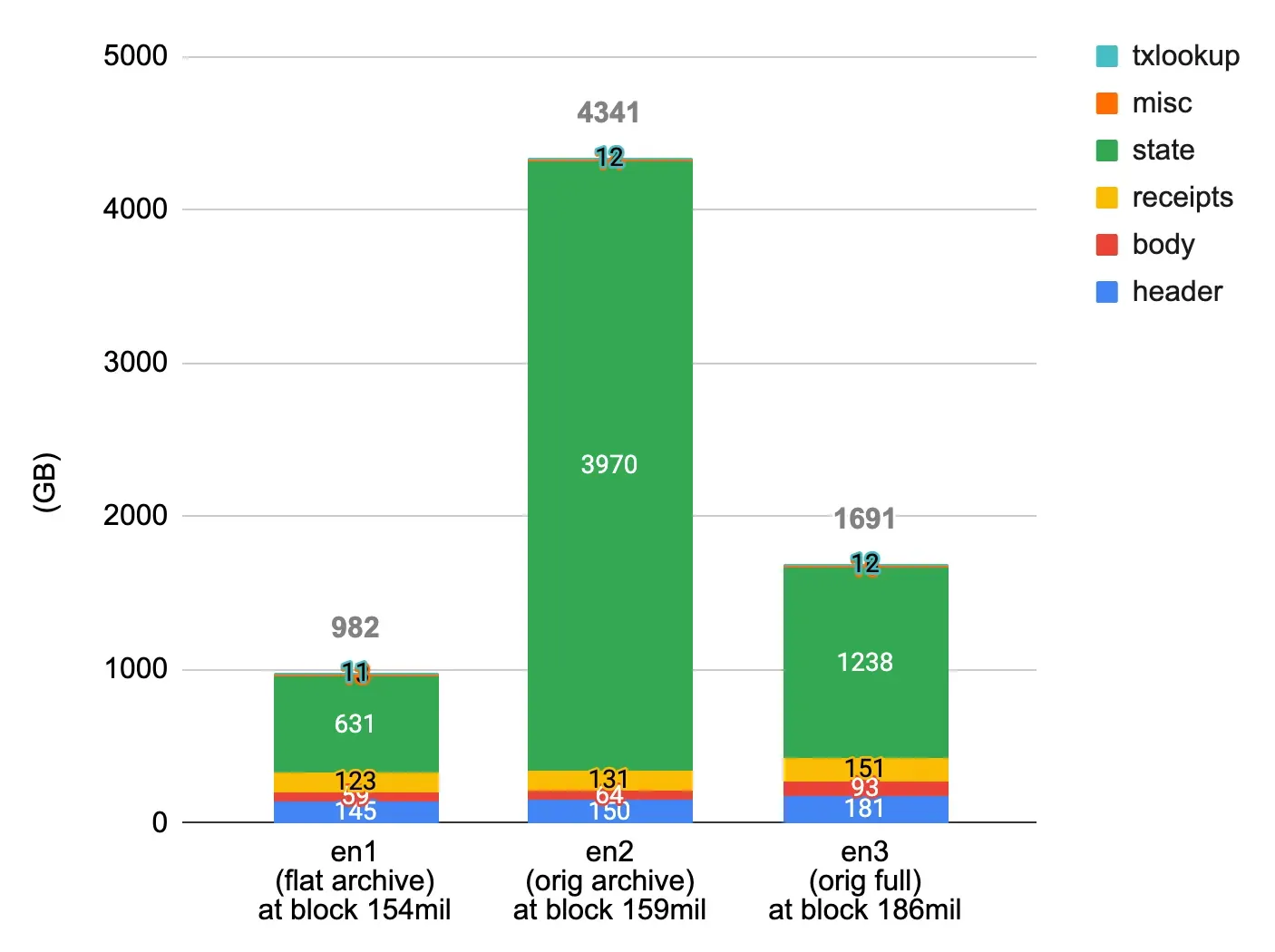
저장소
동일한 블록 높이에서의 저장소 사용량:
- en1 (FlatTrie): 총 982GB, State 631GB
- en2 (기존 아카이브 노드): 총 4,341GB, State 3,970GB
- en3 (기존 풀 노드): 총 1,691GB, State 1,238GB
FlatTrie로 State 용량은 기존 대비 6분의 1, 아카이브 용량은 4분의 1로 감소했습니다.
동기화 속도
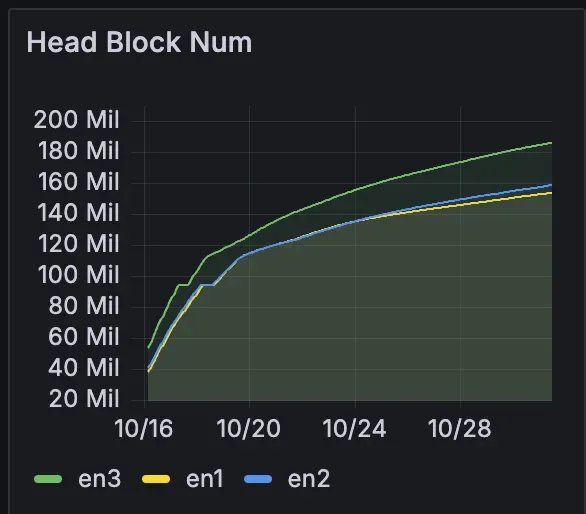
동기화 속도면에서 FlatTrie와 기존 아카이브는 비슷했으며, 둘 다 기존 풀 노드 동기화 속도보다는 약간 느렸습니다. 즉, 새로운 아키텍처로 인한 큰 성능 저하는 없었습니다.
리소스:
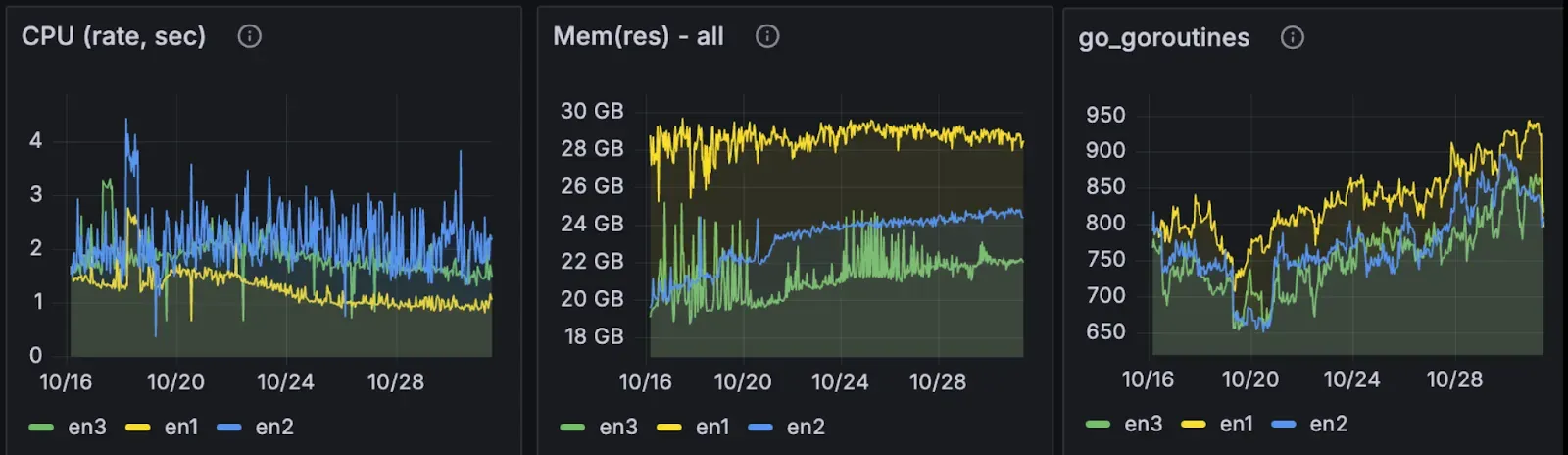
리소스 측면에서 FlatTrie는 다음과 같은 장단점이 있었습니다.
- CPU: 아카이브 모드 및 풀 모드보다 낮음
- 메모리: 더 높음 (~30GB vs 20 ~ 25GB)
- goroutine: 상당히 높음 (~950 vs ~600)
블록 처리
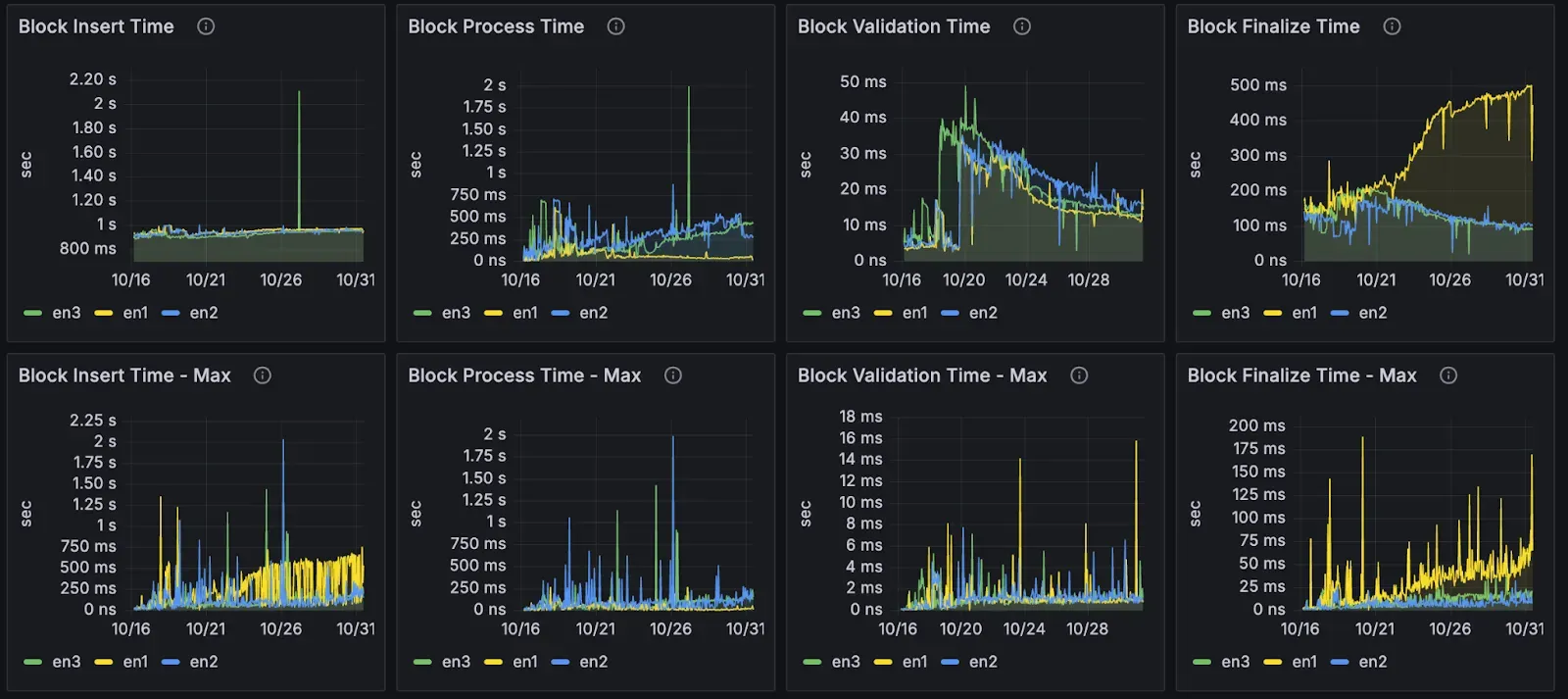
대부분의 타이밍 지표는 허용 가능한 수준이었습니다. 다만 한 가지 문제가 있는데 블록 최종화 시간이 500ms까지 상승했습니다(기존에는 100ms 미만 유지). 이 부분은 가장 우선적으로 최적화할 예정입니다.
제약 사항
현재 FlatTrie를 활성화하면 다음과 기능을 사용할 수 없습니다.
- 블록 되감기 ( — start-block-number, debug_setHead)
- 머클 증명 (eth_getProof)
- 상태 정리(State pruning) (FlatTrie는 아카이브 모드에서만 실행됨)
하지만 이러한 제약이 있다 하더라도 일반적인 아카이브 활용(온체인 분석, 과거 이력 조회, 블록 탐색)에는 문제가 없습니다.
FlatTrie 기능 사용해 보기
FlatTrie는 v2.1.0에서 실험적 기능이며, 빈 데이터베이스 상태에서 제네시스 블록부터 동기화해야 합니다. 즉, 기존 노드에의 변환은 지원되지 않습니다.
## Kairos 테스트넷에서 FlatTrie를 사용하기
ken --state.experimental-flat-trie --kairos이 때 아카이브 모드는 항상 활성화되며 — gcmode 및 — state.block-interval 플래그는 무시됩니다.
설정에 대한 자세한 내용은 Kaia Docs의 노드 저장소 최적화 가이드를 참조하십시오.
향후 계획
v2.1.0의 FlatTrie는 더 효율적인 아카이브 노드 구현를 향한 첫 단추입니다. 현재 Kairos 테스트넷 결과를 분석하면서 메모리 사용량, 리소스 할당, 블록 최종화 속도를 중심으로 최적화가 진행 중입니다. 향후 릴리스에서는 구현을 더욱 다듬은 후, 메인넷 검증 및 스냅샷 배포가 이어질 예정입니다.



