Flatten the State, Shrink the Disk
Kaia’s Experimental FlatTrie for Archive Nodes


The Archive Node Dilemma
Full nodes maintain manageable storage requirements. Archive nodes require 5–10x more. A Kaia mainnet full node uses about 5TB of storage. An archive node requires over 35TB. Most of that space — 31TB — goes to the state database, which stores account balances, contract variables, and every state change at every block height throughout the chain’s history.
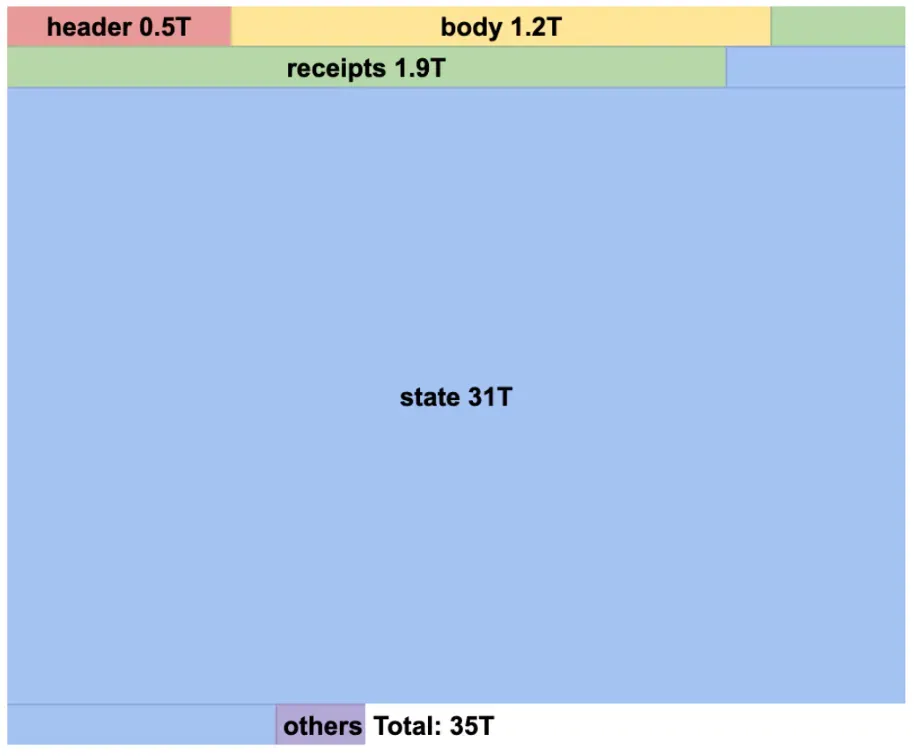
Archive nodes remember complete history. Full nodes can prune old states and stay lean. But for data analytics platforms, block explorers, and forensic tools, archive nodes are required. They need to answer questions like “what was this wallet’s USDC balance on January 1, 2023?”
Kaia’s State Migration (2021) and Live Pruning (2023) helped full nodes by deleting old data. Archives can’t delete anything. Archive nodes require a different approach.
Kaia v2.1.0 introduces FlatTrie — an experimental state storage scheme that could cut archive nodes from 35TB to potentially 10–20TB. Early tests on Kairos testnet show more than 75% reduction in total storage. No data deleted.
The Merkle Trie Bloat Problem
Merkle Patricia Tries (MPT) have historically been used by EVM chains to store state. Each block gets a state root — a 32-byte hash proving the entire world state. To verify that hash, you need the leaf nodes (actual account balances, contract storage) plus all the intermediate branch nodes that connect them into a tree structure.
This causes storage to increase rapidly. Archive nodes store complete tries for hundreds of millions of blocks. When only a few accounts change between blocks, most nodes stay identical — yet they’re stored redundantly for every single block.
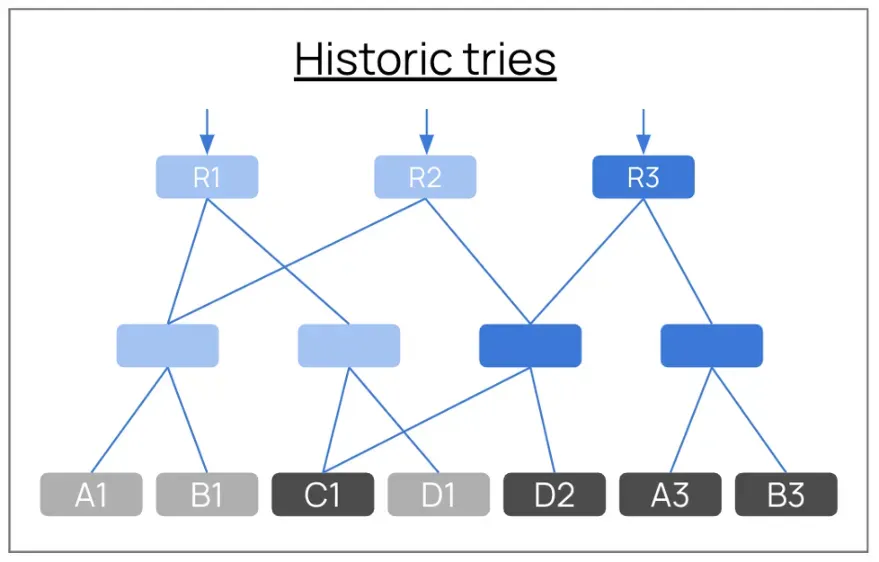
The diagram shows the problem. Block root R1 stores a full trie: branch nodes forming the tree structure, with leaf nodes A1, B1, C1, D1 at the bottom containing actual account data. Block R2 stores another full trie — leaf nodes A1 and B1 haven’t changed, C1 stays the same, but D2 is new. The entire branch node structure is duplicated. Block R3 duplicates the structure again with leaf nodes including unchanged C1 and D2, plus updated A3 and B3. After 200 million blocks, these redundant branch nodes accumulate into terabytes of redundant data.
The Erigon Solution: Store Only Leaf Nodes
Erigon (an Ethereum client) demonstrated that historical branch nodes are unnecessary. The following diagram shows the solution:
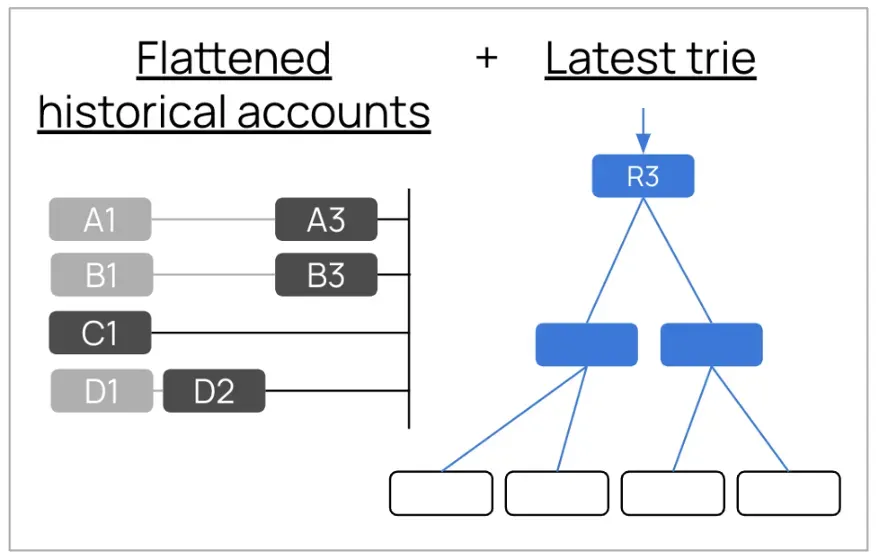
- Flattened historical leaf nodes stored in a deduplicated table — A1 and A3 for account A, B1 and B3 for account B, C1 for account C, D1 and D2 for account D. Each account’s state versions are stored once as flat leaf data.
- The latest trie (R3) maintains only the current block’s complete structure (branch nodes + leaf nodes) for fast writes and Merkle root computation.
- Complete tries for historical blocks R1 and R2 are discarded.
Historical Merkle proofs can be rebuilt on-demand by reconstructing trie chunks from the flat data, though this process is computationally intensive.
Erigon cut Ethereum archives from 13TB to 3TB (2023 data). Go-ethereum recently adopted the idea with their path-based state scheme (June 2025), reporting 20TB to 2TB reductions. Polygon recommends Erigon for archive nodes. These results validate the approach.
Kaia’s Account Format Problem
Adapting Erigon’s approach to Kaia encountered two technical problems. First, Erigon’s code assumes Ethereum’s account structure:
Ethereum: RLP([nonce, balance, storageRoot, codeHash])
Kaia: type || RLP([[nonce, balance, humanReadable, accountKey],
storageRoot, codeHash, codeInfo])Kaia supports unique features like role-based multi-key accounts and the ability to change key pairs without changing addresses. A need for different RLP encoding emerged to accommodate these features. Erigon’s HexPatriciaHashed (HPH) module — the part that calculates Merkle roots — parses Ethereum’s format and cannot process Kaia’s account structure.
Fix: Modified HPH to treat accounts as opaque byte strings. Hash the bytes without parsing the structure. This makes the implementation format-agnostic.
The Threading Constraints
The second challenge: Erigon’s database (MDBX) enforces single-threaded transaction access.
Kaia’s code, derived from go-ethereum, initiates multiple goroutines that require concurrent access to the database. Multiple instances of Trie are generated by various threads. MDBX doesn’t allow this pattern — a transaction must only be used by a single thread.
Fix #1: DomainsManager
Developed worker threads, each owning a distinct MDBX database transaction. Kaia code sends tasks through Go channels. Each worker executes the task within its own transaction context and returns the result, ensuring MDBX’s single-thread requirement is never violated.
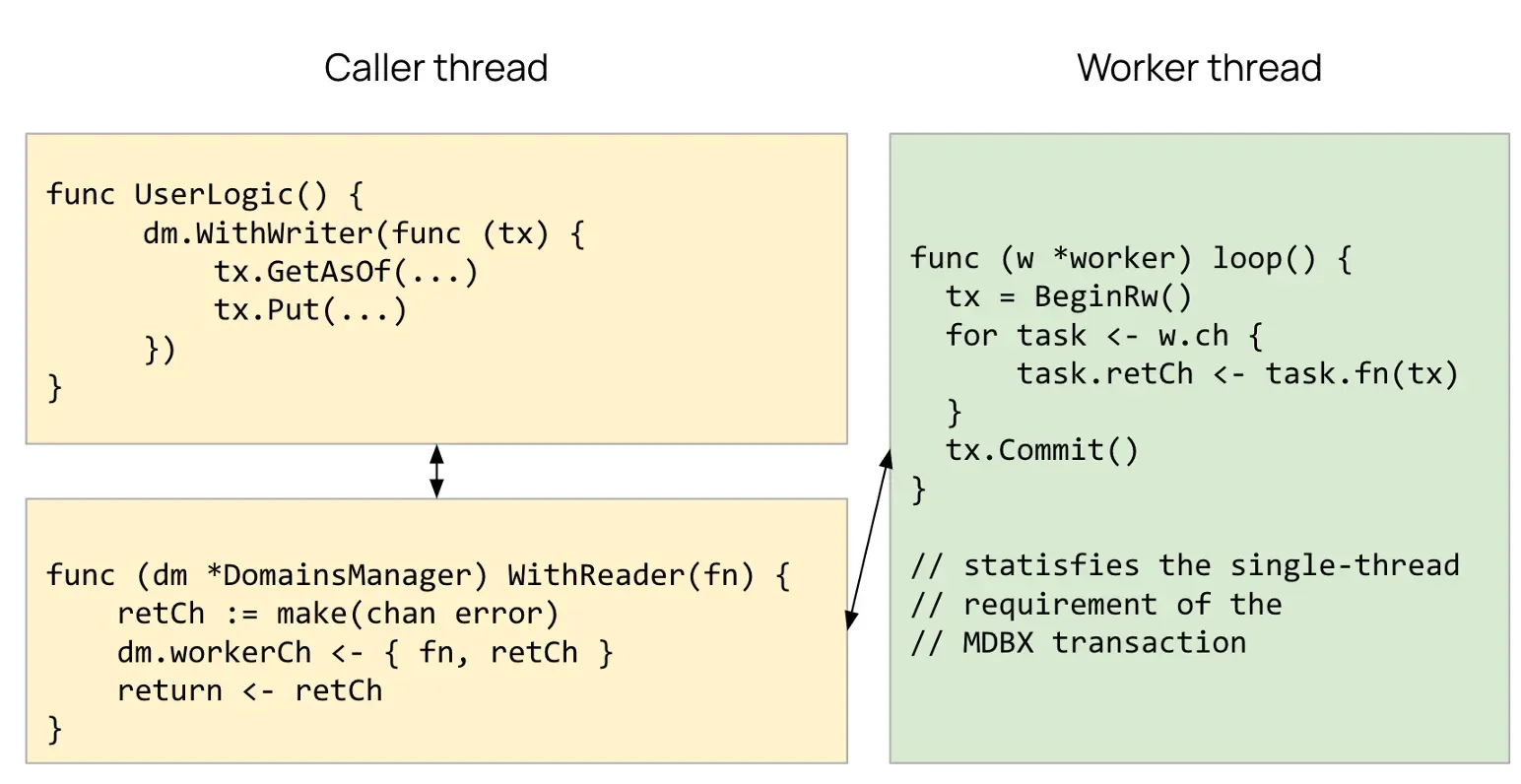
This maintains Kaia’s multi-threaded interface while satisfying MDBX’s single-threaded requirements. This resolves the threading constraint.
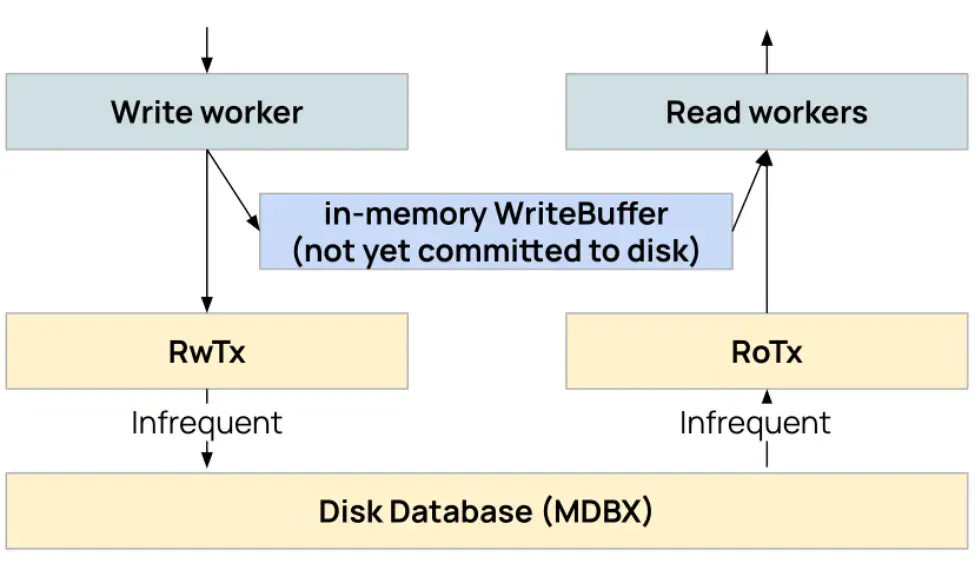
Fix #2: WriteBuffer
A new issue emerged: uncommitted writes in one transaction are not visible to read-only transactions in other workers. Committing after every write caused unacceptable disk I/O overhead.
Added WriteBuffer — in-memory layer shared across workers. Writes go to buffer first. Reads check buffer before disk. Commits occur at regular intervals rather than after each operation.
Fix #3: DeferredContext
Processing one block needs one AccountTrie plus N StorageTries (one per contract). All changes feed into a single HPH to calculate the block’s state root.
DeferredContext coordinates this, bridging between Kaia’s Trie interface and Erigon’s Merkle hasher (HexPatriciaHashed). It gathers updates from all tries, stages them through multiple layers, and feeds HPH at the appropriate time.
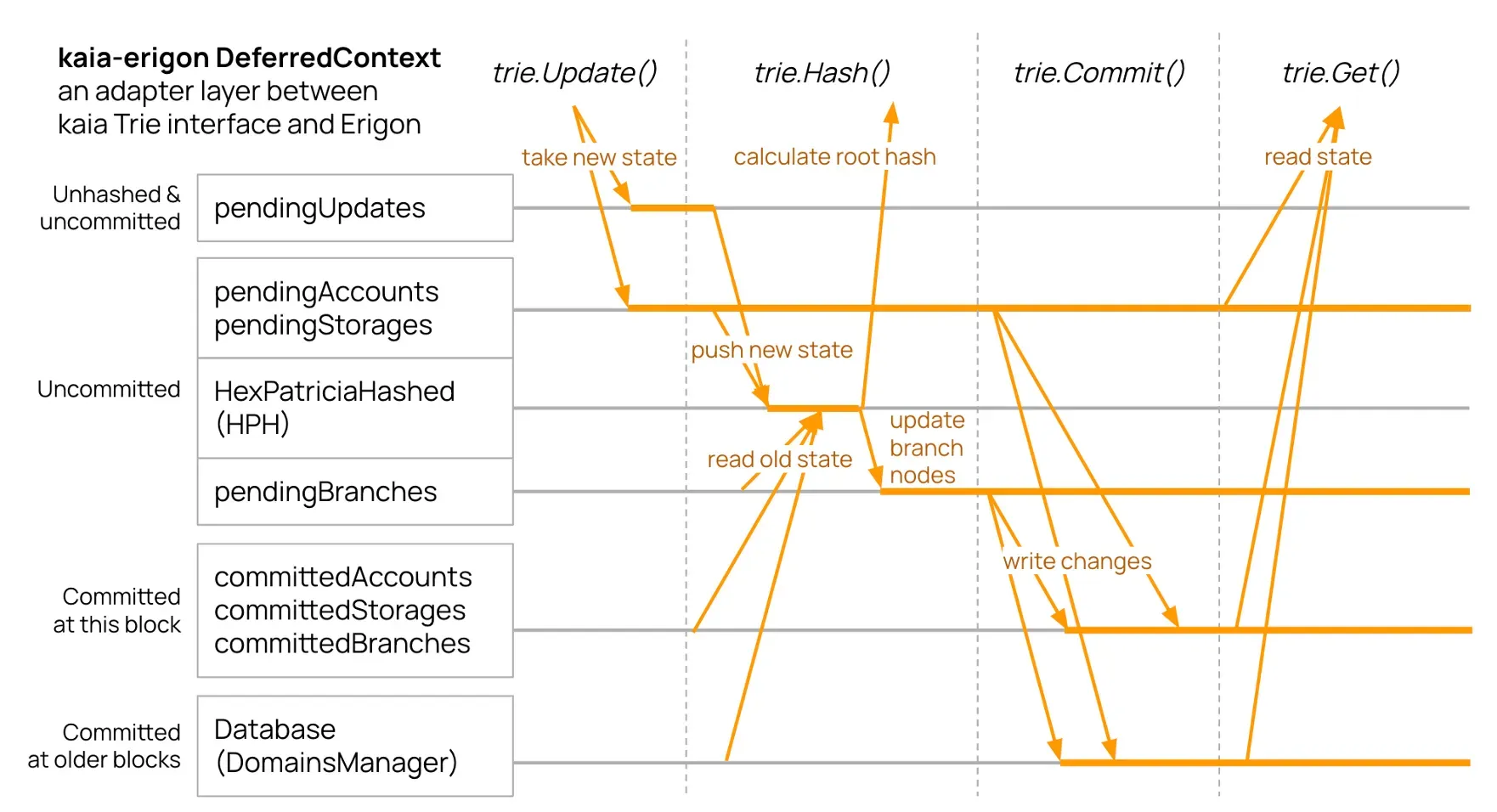
Multiple buffers handle different commitment states: pending unhashed, pending hashed, committed at current block, committed historically. Each Trie operation (Update(), Hash(), Commit(), Get()) navigates these layers correctly.
You can find the full modified code here.
Kairos Test Results
Conducted a multi-week synchronization test on Kairos testnet with three setups:
- en1: FlatTrie archive ( — state.experimental-flat-trie)
- en2: Original archive ( — gcmode archive — state.block-interval 1)
- en3: Original full node (default)
Storage:
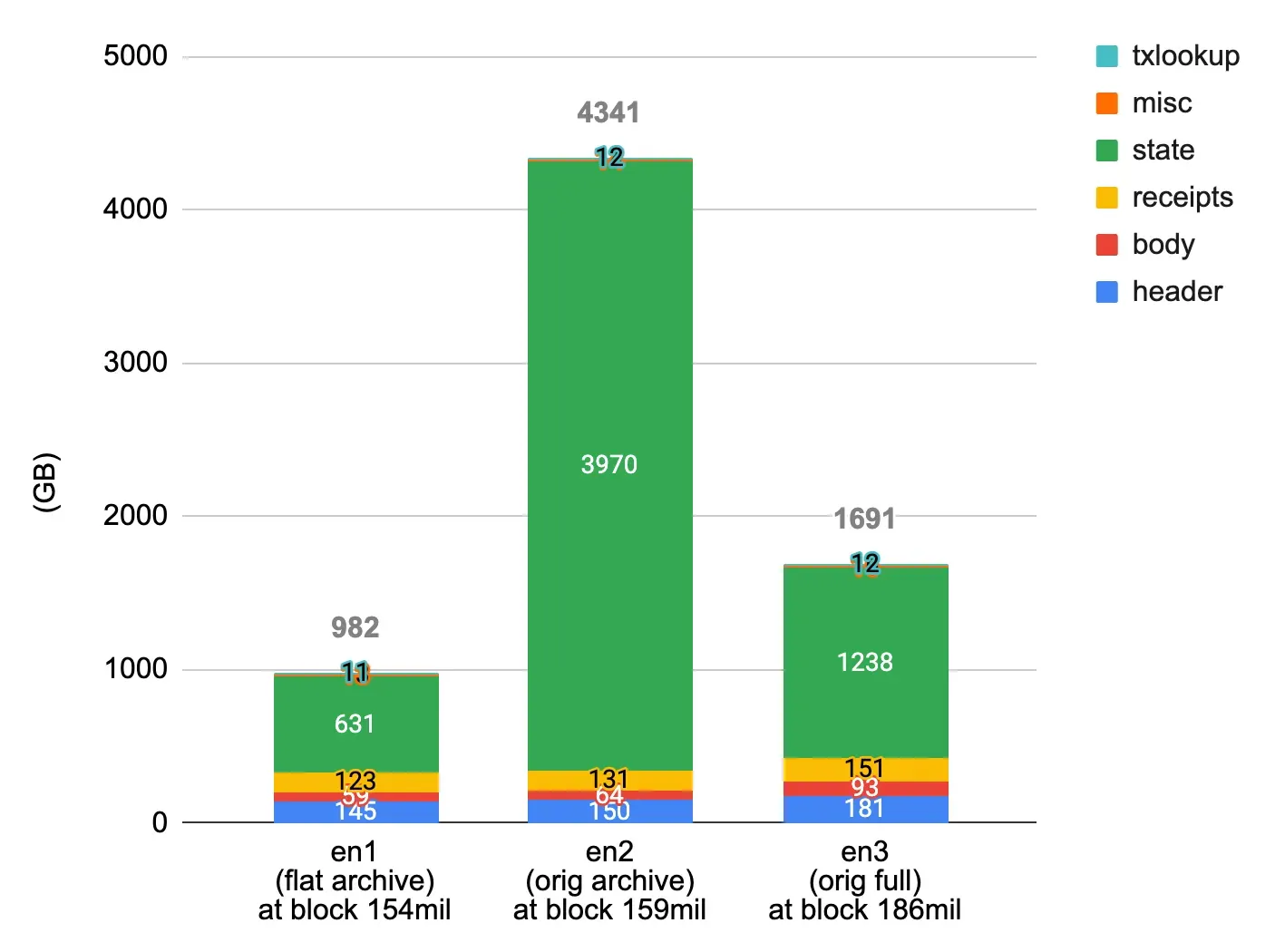
At comparable block heights:
- en1 (FlatTrie): 982GB total, 631GB state
- en2 (Original archive): 4,341GB total, 3,970GB state
- en3 (Original full): 1,691GB total, 1,238GB state
FlatTrie cut state size by 6x. Total size by 4x compared to original archive.
Sync Speed:
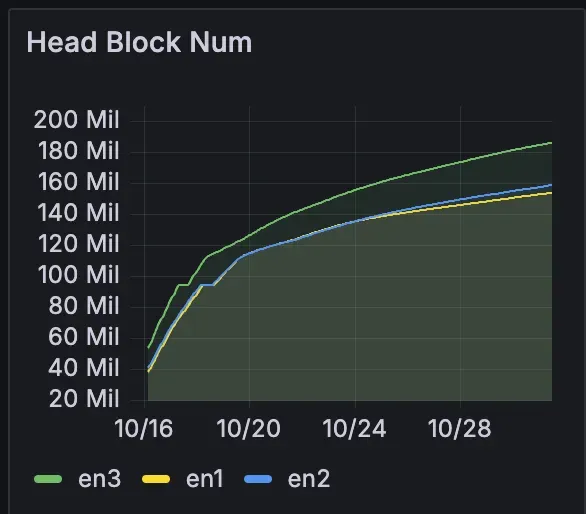
FlatTrie and original archive synced at similar speeds, both slightly slower than full node. No major performance hit from the new architecture.
Resources:
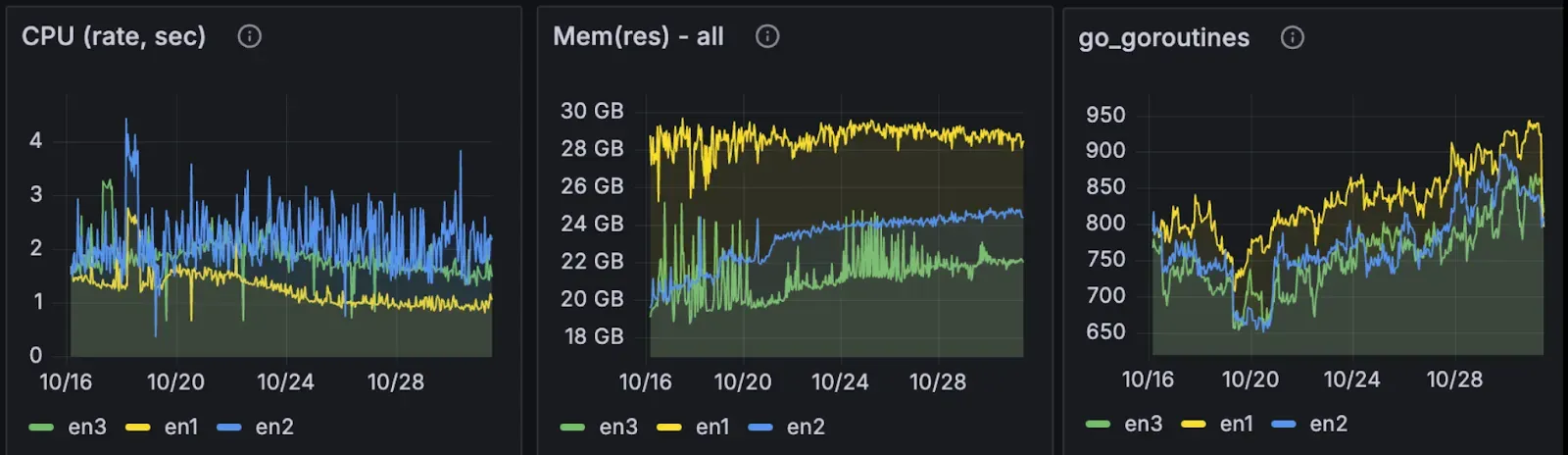
The implementation exhibited trade-offs:
- CPU: Lower than both archive and full modes
- Memory: Higher (~30GB vs 20–25GB)
- Goroutines: Substantially higher (~950 vs ~600)
Block Processing:
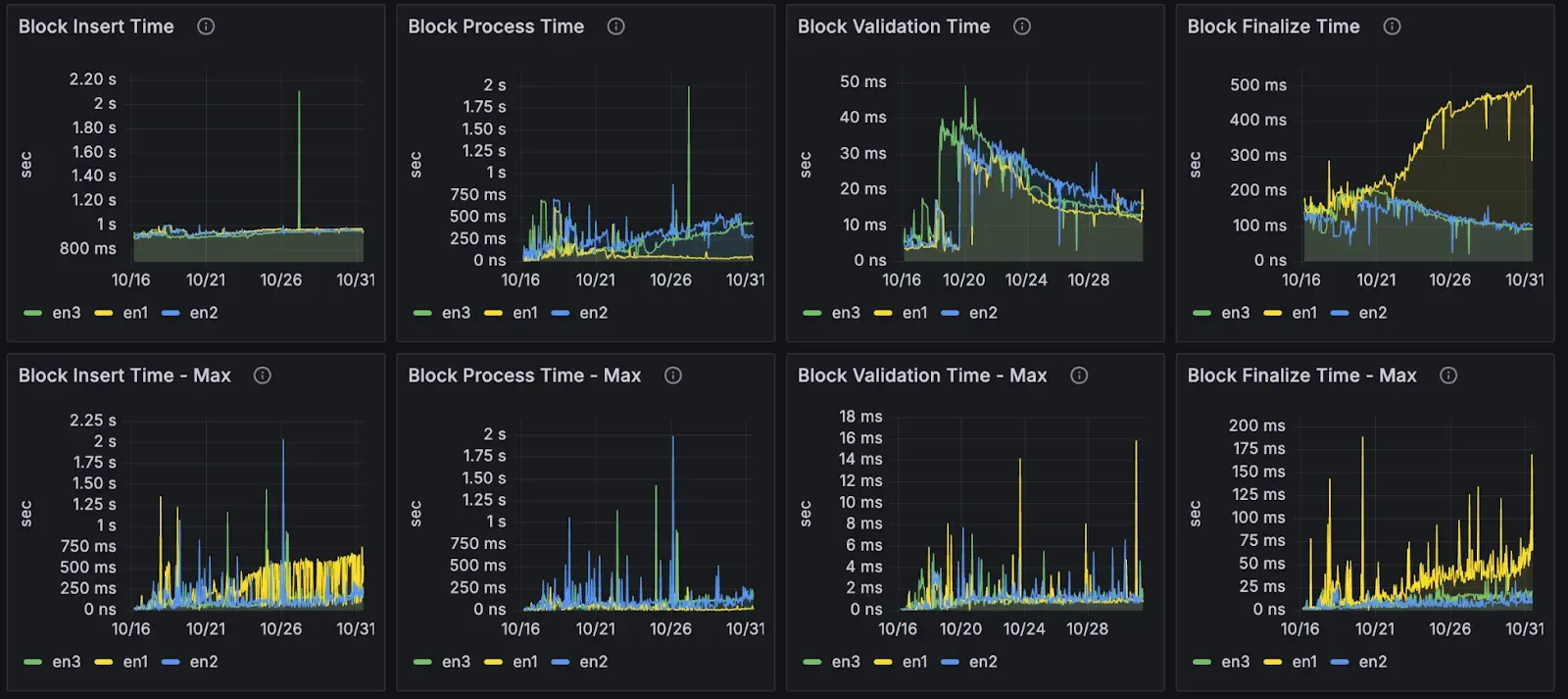
Most timing metrics were acceptable. One issue emerged: block finalization time climbed to ~500ms (originals stayed under 100ms). This represents the primary optimization target.
Current Limitations
FlatTrie disables several features:
- Block rewinding ( — start-block-number, debug_setHead)
- Merkle proofs (eth_getProof)
- State pruning (FlatTrie runs in archive mode only)
But, these limitations do not affect typical archive use cases — analytics, historical queries, block explorers.
What to Do
FlatTrie is experimental in v2.1.0 and requires syncing from genesis with an empty database, that is, conversion of existing nodes is not supported.
# Mainnet with FlatTrie
ken --state.experimental-flat-trie
# Kairos testnet with FlatTrie
ken --state.experimental-flat-trie --kairosArchive mode is always enabled. The — gcmode and — state.block-interval flags are ignored when FlatTrie is active.
See the Optimize Node Storage guide in Kaia docs for setup details.
What’s Next
FlatTrie in v2.1.0 represents an initial implementation toward more efficient archive nodes. The team is analyzing Kairos results and optimizing memory usage, resource allocation, and block finalization speed. Future releases will refine the implementation, with mainnet validation and potential snapshot distribution to follow.
The underlying approach has been validated — Erigon runs Ethereum archives, Polygon recommends it for archive nodes. The implementation is being optimized for Kaia’s requirements.